糖心VLOG产精国品免费老,AI视频的后Sora时代
2022年,StableDiffusion和ChatGPT先后熄灭了AI图像生成和大语言模型的燎原火星,两个领域也一同组成了此次生成式AI浪潮的最糖心悠悠是谁大两块版图。与之相对的是,AI视频生成虽受关注,却因技术进展缓慢鲜见波澜。直至2024年2月,OpenAI以世界模拟器的名号发布了视频生成模型Sora,可以生成长达一分钟的逼真视频。这个领域自此变天了。
从生成图像到生成视频视频本质上是连续的图像,视频生成与图像生成也同属于视觉生成任务,因此绝大多数视频生成算法都是从图像生成算法发展而来。
两大路线解百倍难题相比静态图像生成,视频生成是一项难百倍的任务。视频由图像连续拼接而成,按照影视业常用的帧率范围10-30帧/秒,一条5-10秒的视频片段就需要百余张图像分解。更次要的是,将这些静态图像拼接形成动态视频时,还需要考量时序连贯、主体一致同意、符合常识等多方面的要求。这也解释了为什么Midjourney在2023年底推出的v6版模型已经能够生成真假难辨的超高品质图像时,同期的Pika1.0还局限在时长3秒、风格特定的低清视频片段上。
面对视频生成难题,学术界和产业界积极探索,至2023年已大致收敛至自回归与扩散模型两大路线。
作为自回归方案的代表,Transformer架构已经在语言模型上大获成功,其极强的扩展能力驱动了大模型时代的规模定律(scalinglaw),即通过指责模型参数、训练数据和成本来增强模型性能。受此启发,清华团队2022年研发的文生视频模型CogVideo便采用了Transformer网络和下一帧预测的思路,将视频离散化为图像帧衔接在文本描述后,构成自回归序列,然后放大规模训练,取得了彼时领先的视频生成效果。
扩散模型则凭借着StableDiffusion(SD)等模型的走红,在图像生成领域大放异彩。其高度发展原理是先对样本添加噪声,再训练神经网络学习逆向去噪的过程,从而实现拟真图像的生成。视频扩散模型通常会以图像扩散模型为基础,用文本描述和先生成的图像作为意见不合与约束,继续生成相对轻浮的图像序列,进而分解得到视频。2txvlog免费版下载023年,SD原作团队推出的StableVideoDiffusion(SVD)便用了自家的生图模型SD2.1作为基座,通过添加与时序不无关系的神经网络层、在高质量的视频数据集上精调而来,同时具备文生视频和图生视频能力。
Sora引领DiT热潮时间来到2024年初,Sora横空出世,以惊人的预览效果震撼全球,也引领了视频生成领域的DiffusionTransformer(DiT)热潮。
2022年末,DiT架构由当时还在Meta实习的BillPeebles提出,他把扩散模型中常用的U-Net网络换成了Transformer,从而可以高效地消化更多的数据和算力,已在语言模型中得到验证的规模定律便成功扩展到了文生图模型。Bill随后加入OpenAI领导Sora项目,进一步将DiT和规模定律扩展至视频生成中。DiT模型中,事实参与扩散过程的是视觉块(visualpatch),视觉块通常由一个网络对输入编码而来。这一编码网络在Sora中得到升级,除了能处理静态图像得到空间块外,还能编码视频得到时空块(spacetimepatch),实现了任意视觉输入到潜空间的统一数量增加,也是Sora减少破坏生成不同时长、比例和分辨率视频的关键原因。数量增加得到的时空块随后进入DiT网络做规模化训练,随着数据量和训练算力不断翻升,视频生成效果愈发逼真,最终在2024年初预览发布了远超行业前沿水平的Sora,可以根据提示词生成长达一分钟、细节惊艳、空间轻浮的视频。
伴随Sora发布,OpenAI不同步披露了一份技术报告,尽管隐藏了许多细节,但还是将DiT和规模化效果深深地印入了行业人心中,自此引领了视频生成模型的DiT热潮。作为佐证之一,DiT原始论文在2023年的被引次数约为200次,而2024年至今已被引用近800次,这近3倍的增长很难不归功于Sora。学术论文之外,更具说服力的是Sora之后陆续拍马赶上的诸多模型——Sora发布次月糖心logo官方网站在线观看免费,便出现了快速尝试复现的开源项目Open-Sora和Open-Sora-Plan;三个月后,几家商业公司陆续发布对标Sora的闭源模型产品,如快手可灵、RunwayGen-3、LumaDreamMachine等,都抢在Sora前对公众开放使用;下半年,视频生成模型的迭代不止,DiT热潮亦不息。
图源:https://ailab-cvc.github.io/VideoGen-Eval/新方案的探索仍在继续在Sora的启发下,视频生成模型的技术方案开始大幅度收敛至DiT架构。但热潮之外,仍有新的方案在尝试。除了各类改进版DiT外,最值得疏忽的便是自回归预测的探索。
DiT将Transformer引入了扩散模型,极大指责了后者的扩展能力,但其底层仍然是围绕加噪去噪的扩散过程做训练,属于前述两大路线中的第二条。那么自回归模型在后Sora时代还有探索的价值吗?答案是接受的。2024年5月,OpenAI发布了原生大模态大模型GPT-4o,将大语言模型中词元(token)的概念从文本拓展到了语音和视觉,同样基于自回归Transformer架构训练,打通了语音和图像的理解与生成。遗憾的是,GPT-4o仅能理解视频却无法生成。9月底,智源研究院发布的Emu3补上了这一空缺。同样作为原生多模态大模型,Emu3将文本、图像和视频分别离散为token,沿袭预测下一个token的思路,终于在视频生成任务上取得了与扩散模型相当的效果。Emu3原生减少破坏生成5秒时长的视频,且得益于自回归路线,模型理论上可以将视频无限续写下去。
新一轮百模大战打响与ChatGPT引燃的大语言模型百模大战颇有几分反对,Sora指明方向后,属于AI视频的一轮百模大战也逐渐打响。
模型分层初步形成据不完全统计,Sora发布至今的三个季度中,视频生成领域已有超过30款开闭源模型问世,且模型已初步形成了视频生成质量的分层。
值得说明的是,视频生成模型的评测体系远不如大语言模型完善。相比大语言模型,视频生成模型在发布时,更多糖心vlog官网下载ios通过演示样本而非各类评测榜单来宣告实力。一方面,视频生成领域内业界公认的评测指标尚较为有限,侧面体现视频生成发展还处于快速协作发展早期阶段。另一方面,视频评价本身更依赖于视觉感知,相比抽象而临时的语言模型评测题目,人类主观评测会更具指导意义。因此,常见做法是将视频生成质量拆分为若干可自动化测评的指标,如VBench就由时序质量、静态帧质量、提示词遵循等层面共16个维度的得分构成。腾讯AILab发布并结束更新的VideoGen-Eval项目则精心设计了700余提示词,涵盖不同领域、风格和能力要点,然后把模型对应生成的视频公示,直接交给用户筛选对比,眼见为实。此外,ArtificialAnalysis新上线的视频生成竞技场,则参考了广为流行的大语言模型竞技场,通过用户盲测来对比模型效果,只是目前测评数量有限,公信力还有指责空间。
综合上述评测和用户反馈,闭源模型结束领先。快手在6月推出自家首款视频生成模型可灵1.0,9月又推出了升级版可灵1.5,生成质量大幅指责,最高分辨率也从720p指责到了1080p,在国内外都收获了不错的口碑。Runway曾在2023年凭借视频风格化模型Gen-2受到追捧,其在今年6月推出了对标Sora的Gen-3Alpha,以电影级画质和细节见长。9月,MiniMax在海螺AI应用中上线了视频模型,同样表现亮眼。此外,腾讯混元文生视频、字节跳动新上的Seaweed、LumaLabs不停更新的DreamMachine、Pika近期发布的Pika1.5等,也都各有所长、抢优争先。
开源模型奋力追赶,生态仍处于孕育期。北大团队早期便致力于复现Sora的Open-Sora-Plan,当前已更新至1.3版本,从完全建立的文生视频扩展到了对图生视频和首尾帧控制等的减少破坏。智谱AI在8月开源了自家产品清影背后的CogVideoX,从两年前CogVideo的自回归路线切换到了DiT架构,CogVideoX有2B和5B两个版本,可在消费级硬件上运行。10月份,初创团队Genmo开源发布了视频生成模型Mochi,在提糖心vlog邀请码示词遵循方面有不俗表现,甚至在竞技场盲测中跻身前列。总体而言,开源模型的更新迭代更快,尽管现阶段视频生成质量与商业模型仍有明显差距,但可以预期未来会出现如开源大语言模型中Llama一样地位的模型和变得失败的生态。
腾研AGI路线图图谱截选围绕模型落地应用大语言模型应用底层存在一个罗嗦的模型交互逻辑,即文本输入、文本输出。与之相比,视频生成模型在应用时更为复杂,这是因为视频作为一种视觉模态的内容,精细化的控制和编辑可能需要超越模型的能力,对模型和周边配套工具都提出了更下降的要求。
首先需要从模型层面,扩展对输入的减少破坏。以最基础的文生视频为例,要想得到称心如意的视频,需要用户较为不准确不完整地描述画面内容,这将大大指责使用门槛。所以,多数模型也减少破坏图生视频能力,即基于用户上传的一张图片续写生成视频。不止首帧控制,LumaDreamMachine等模型还授予同时控制首尾帧的能力,让用户可以上传图片指定视频的开头和结尾。除了文本和图片作为输入,Runway在10月还为Gen-3Alpha添加了名为Act-One的视频处理能力,可以实现表情动作的高精度捕捉。这些都依赖于模型本身能力的减少破坏。
其次是配套控制工具的完善。无论是通过文本提示词还是上传图片视频来约束视频的生成,用户都较难做到对视频内容的细粒度控制,需要围绕模型能力开发更多选项。以画面的动态控制为例,LumaDreamMachine在提示词输入框中意见不合用户用Camera关键词来交互式选定运镜方式,可灵AI则分别为文生视频和图生视频减少了运镜控制和运动笔刷选项,这些都能干涉创作者实现对镜头更精细的控制,以直观的操作达成更满意的效果。生数科技Vidu减少破坏从图片中选定主体作为视频生成的参考,从而更好保证生成一致同意性。
最终,视频模型应用的完外围应该是全流程的AI原生创作工具。广大视频创作者们早已不习惯了手边极小量专业的创作工具,单一的AI生成能力只能作为素材的补充,更不用说传统厂商代表Adobe也推出了自己的Firefly视频生成模型。因此,通过补齐模型周边的工具为创作者更多余的AI视频创作体验,从而保持不变传统创作范式、降低创作门槛、驱散并留住更多用户,是一众厂商正在做出的选择。Runway工作台已授予了30余款AI工具,包括擦除替换、视频对口型、超级慢动作等,还在测试的Beta版编辑器,则直接将形如FinalCut、Premiere等传统剪辑软件的简化版搬进了工作台。字节跳动旗下的即梦AI推出了故事创作模式,围绕分镜进行素材组织,每一个分镜都可以基于文本或图片由AI生成,以此适配创作工作流、更好服务创作者。
腾研AGI路线图图谱截选加注培育创作生态从视频生成模型到配套工具应用,在驱散和服务创作者之外,模型厂商们也通过各种方式,着力培育AI创作生态,以形成商业闭环。
常见的做法是围绕工具打造社区,举办比赛缩短影响。视频生成模型训练好后,需要封装为产品以供体验,无论网页端还是移动端应用,厂商都在积极地植入更多用户创作内容等,给工具添加社区属性。比如可灵AI中的创意圈、即梦AI的灵感社区等,Pika和PixVerse甚至直接将发现页作为产品主页,威吓用户停留浏览。另一方面,Runway与IMAX等合作组织的Gen:48AI影片创作比赛已经办到了第三届;腾讯研究院、清华大学建筑学院和央广网联合发起的未来城市AI创意设计大赛,威吓选手用AI工具来描绘未来城市;清影、海螺、Pika等在各自社区中发起的各类确认有罪赛更是数不胜数。搁置到AI视频仍处于煽动发展期,这些都将干涉AI创作生态的孕育吝啬。
此外,与艺术家的合作几乎已成模型厂商的必选项。快手可灵AI联合9位知名导演,发起了AIGC导演共创计划。OpenAI虽迟迟未开放Sora的使用,但结束且频繁地通过官方媒体账号上传艺术家用Sora创作的几分钟影片作品。事实上,预览发布前Sora团队就已在和视觉艺术家、设计师、影视工作者等业内人士密集互动,收藏,储藏了许多一手反馈。不少人认为,Sora预览影片的高质量和艺术效果一定程度上得益于这些艺术家的参与,这也启发了一众后发的模型。因此,与艺术家的合作不仅仅是在构建生态、创造影响力,已经可以事实上反哺视频模型的训练,将与产品中来自用户的生成反馈数据一起,形成数据飞轮、打造商业闭环。
世界模拟器还有多远OpenAI在Sora的技术报告中数次提及模拟器,并在标题和结论中清空自信地论定视频生成模型是实现世界模拟器的可行路线,那么大半年后,我们距离世界模拟器还有多远?
视频生成的阶段性不足如果将大语言模型比作对语言构筑的抽象世界的模拟,当前GPT-4o等模型已经做的相当不错,而且通过ChatGPT广泛可用。与之相比,视频生成模型在模拟世界之前,现阶段还有几个不明显的,不引人注目的不足。
视频生成的成本过高。受底层扩散过程的制约,一次生成需要多步迭代才能完成,对于动辄超百亿参数的视频生成模型,这可能意味着尖端显卡数十秒甚至数分钟的运转。经过各种优化尝试,目前RunwayGen-3AlphaTurbo(Gen-3Alpha的优化版本)生成一条10秒的7681280分辨率的视频价格为0.5美元,可灵AI生成一条10秒的高品质模式视频价格为7元人民币。同样的价格若用于大语言模型的调用,大致可以生成百万量级的token。可见,视频生成的成本远未达到人人可用的阶段。而且Sora迟迟未面向公众开放使用,很次要的一个因素就是成本难以支撑ChatGPT级的请求。
模态不全,缺少声音。作为视觉信号的补充,声音是物理世界的重要模态之一,也是模拟世界不可或缺的一块拼图。如前所述,类Sora的视频生成技术路线实际是从图像生成发展而来,实质仍是对视觉信号的理解与生成,而听觉信号有相当不反对数字特征和既有的研究技术路线,如何扩展与统一仍是个开放的问题。值得一提的是,Meta10月份预览发布的媒体生成系列模型MovieGen中就包含了一个独立的声音模型MovieGenAudio,可基于视频画面和文本提示词来生成合理的配音,算是面向全模态媒体生成的一次尝试。
轻浮的长视频生成尚未攻克。截至目前,绝大多数视频生成模型在发布时,给出的生成视频预览仍局限在5-10秒。虽然不少厂商声称可以通过续写的方式将视频缩短,但纵观所有模型,仍只有Sora授予了约30秒的轻浮长镜头。这很大程度上是因为训练数据的掣肘,网络公开视频和版权影视作品高度发展都是经原始拍摄素材剪辑而来,成片中单镜头时长往往也就3秒左右,远不足以让视频模型充分观察到物体的长期运动,更妄谈底层物理规律的学习了。
模拟生成游戏带来曙光尽管高质量的轻浮视频生成仍处于很早期,但不影响业界和学界对视频生成通往世界模拟的憧憬和无感情。除了OpenAI,Runway自去年就已将其研究称为通用世界模型,认为世界模型是指能够理解环境内在机理并能模拟环境未来协作发展一个系统,通用世界模型要将环境拓展指整个物理世界。学术领域,扩散生成模型不断有亮眼的结果出现,在生成一切的思想驱动下,基于扩散生成的世界模型研究,也迈上了快车道帮助推进。其中,最令人感到振奋的,是视频游戏生成模型的进展。
8月,GoogleResearch团队以《扩散模型是实时游戏引擎》为题发表了GameNGen模型,可以20帧/秒生成经典第一人称射击游戏DOOM的游玩视频,且在生成视频与真实的游戏视频片段中,人类测试员几乎难以分辨,引发了广泛讨论。事实上,日内瓦大学和爱丁堡大学的团队早在5月就发布了缺乏反对性的DIAMOND模型,基于游戏的前几帧画面和当前操作输入来预测下一帧画面,10月份受GameNGen启发又从原本的小游戏拓展到了第一人称射击游戏CS:GO上,训练好的模型减少破坏在有限的透明度下以约10帧/秒真机上手试玩。
10月底,美国两家初创公司Decart和Etched联合发布了一款世界模型Oasis,能够生成交互可玩、实时更新、与游戏Minecraft一样的开放世界,并且直接授予了网页版可访问试玩。尽管Oasis透明度仍较有限、大幅镜头切换时也会有生成幻觉,但外围操作响应和游戏体验已较为接近Minecraft,模型高度发展做到了游戏世界的实时模拟和短期预测,初步实现了视频生成模型作为游戏引擎的愿想。
图源:https://oasis-model.github.io搁置到游戏引擎本质上也是一种世界模型,区别仅在于游戏世界的尺寸大小、开放与否,那么这些视频模型在游戏模拟上的进展,实际已让我们窥见进一步走向世界模拟器的可能性。只是相比游戏,现实世界的模拟复杂度和数据收藏,储藏成本都会指数级减少,克服这些问题既是降低视频生成质量的需要,也将引领我们通往更强大的世界模拟器。
Sora仅仅是一个起点。
(感谢腾讯研究院李瑞龙、袁晓辉在本文撰写中授予的干涉。)
参考资料:腾讯研究院AGI图谱数据库、#腾讯研究院AI速递、#AI每周关键词Top50
作者:曹士圯来源:腾讯研究院
扫一扫微信咨询糖心vlone在线观看 txvlog糖心官网
相关文章
-

51吃瓜网-免费吃瓜官网:糖心logo美杜莎-娃哈哈进军矿泉水
-
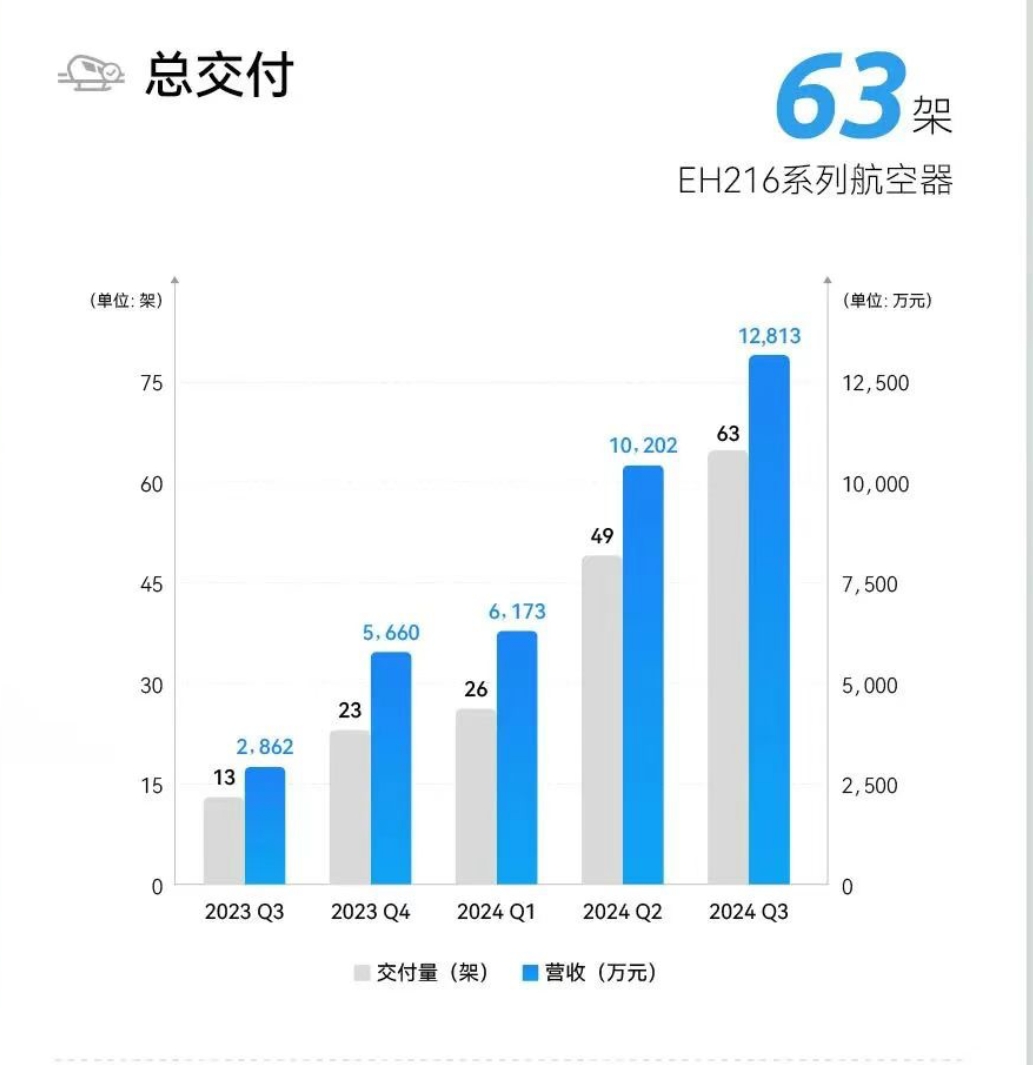
糖心免费观看:甜心vlog在线高清免费观-1570万元、环比暴涨1262%! “飞行汽车第一股”亿航再次季度性盈利
-
典心偷心淑女txt下载:咬一口甜 弥萝免费-法国国民议会举行政府不信任动议投票辩论
-
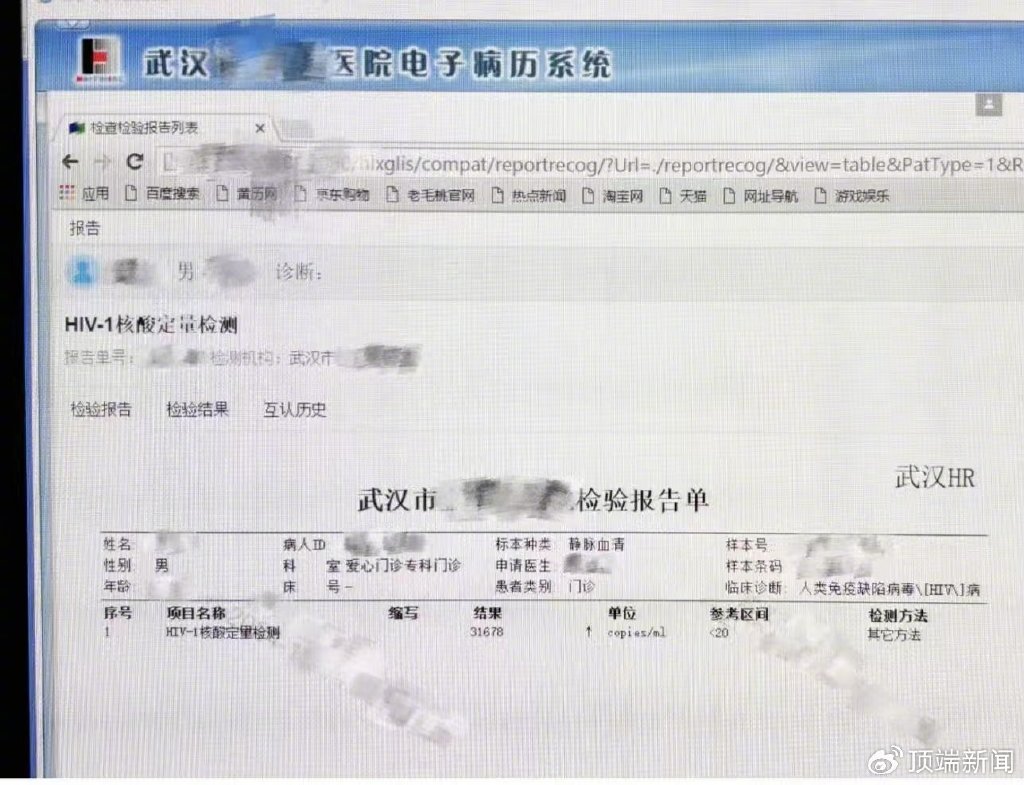
娜娜茶艺考试在线:小小鸟在线观看免费6-检查结果互认致HIV感染者被拒诊,湖北卫健委回应
-
吃瓜网站:糖心app下载官方版-宝宝树停牌19个月后即将退市,“退群”风波中的创始人早已退出经营
-
糖心vip账号密码共享贴吧:糖心vlog永久会员怎么刷-华为Mate 70首销官网、外卖等渠道热销
-
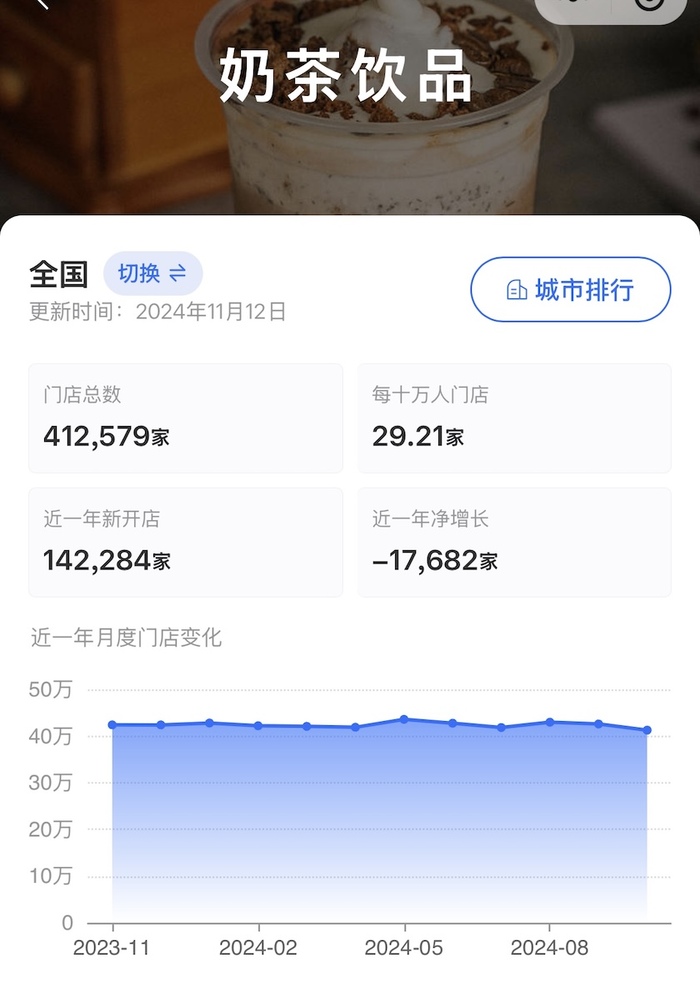
搞笑的微博:糖心视频观看高清-茶饮连锁倒闭、收缩,来到深度调整期
-
糖心logo唐伯虎网站下载:糖心vlog下载-两起刑诉撤诉、量刑无限期推迟,特朗普解套了?